
ArXiv
Preprint
Source Code
Github
Understanding the Diversity-Efficiency Tradeoff in Diffusion Models
Diffusion models face a fundamental challenge: faster generation through distillation leads to "mode collapse" - producing nearly identical images despite different random seeds. These accelerated models sacrifice creative diversity for speed, limiting their practical usefulness.
Our research explores what happens during those crucial early generation steps that so dramatically affects diversity. We've discovered surprising insights about when and how variety emerges during the diffusion process, challenging the assumed tradeoff between computational efficiency and creative expression.

Understanding the Diversity Loss Problem
Diffusion models work by gradually removing noise from a random starting point, step by step, until a clear image emerges. This process can require dozens or even hundreds of sequential steps, making it computationally expensive. When researchers "distill" these models to work in fewer steps, they essentially compress this denoising process.
The acceleration comes with a notable cost: the distilled models begin producing images that look very similar to each other, even when starting from different random noise patterns. This lack of variation limits their creative usefulness, as generating multiple options from the same prompt often yields nearly identical results.
Think of it like this: the original diffusion model is like an artist who carefully considers many possible interpretations of a concept before settling on a final painting. The distilled model, in contrast, rushes to the same conclusion every time, skipping the creative exploration phase.
A Surprising Discovery: Preserved Internal Knowledge
Our first key finding was unexpected: despite producing less diverse outputs, distilled models still maintain the same internal understanding of concepts as their slower counterparts. We discovered this by testing whether control mechanisms (like sliders that adjust specific image attributes) trained on the slow models would work on the fast ones, and vice versa.
The results were clear: controls for adjusting features like "big eyes," "pixel art style," or specific character attributes worked seamlessly across model types without any retraining. This demonstrated that the distilled models hadn't lost their understanding of these concepts—they just weren't expressing the full range of possibilities in their outputs.
Introducing DT-Visualization: Seeing Inside the Black Box
To understand why diversity collapses despite preserved knowledge, we developed a new technique called DT-Visualization (Diffusion Target Visualization). This method reveals what the model "thinks" the final image will look like at any intermediate step in the generation process.
Think of it as taking a time machine to the middle of the creation process and asking: "Based on what you've done so far, what do you think the final image will be?" Our technique allows us to see these predictions without waiting for the full generation to complete.
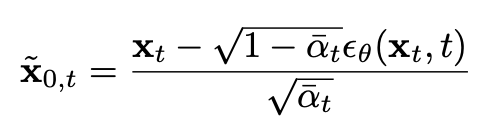
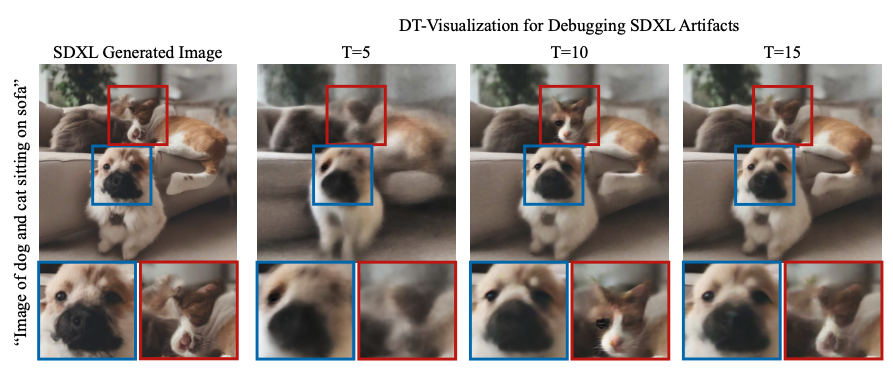
Using DT-Visualization to Debug Generation Issues
This visualization technique proves valuable as a debugging tool. For example, when we asked a model to generate "an image of a dog and cat sitting on a sofa," the final image contained only a dog. Using DT-Visualization, we could see that the model had actually started to create a cat face around the middle of the process, but later changed its mind and removed it.
This insight helps explain why diffusion models sometimes "forget" to include elements mentioned in the prompt—they begin creating certain features but abandon them during later refinement steps.
The Key to Diversity: Early Generation Steps
When we applied DT-Visualization to compare base and distilled models, we discovered something crucial: the initial diffusion steps disproportionately determine the overall structure and diversity of the image, while later steps mainly refine details.
Distilled models appear to commit to a final image structure almost immediately after the first denoising step, while base models explore and develop structural elements across multiple steps. This early commitment explains the lack of diversity—distilled models essentially "make up their mind" too quickly about what the image will be.

Our Solution: Diversity Distillation
Based on our findings, we developed a hybrid approach called "Diversity Distillation." This method uses the base model for just the first critical timestep—where the most important structural decisions are made—and then switches to the faster distilled model for all remaining steps.
By letting the slow model handle the crucial creative exploration phase and the fast model handle the detail refinement, we get the best of both worlds: the diversity of base models with nearly the speed of distilled ones.

Remarkable Results
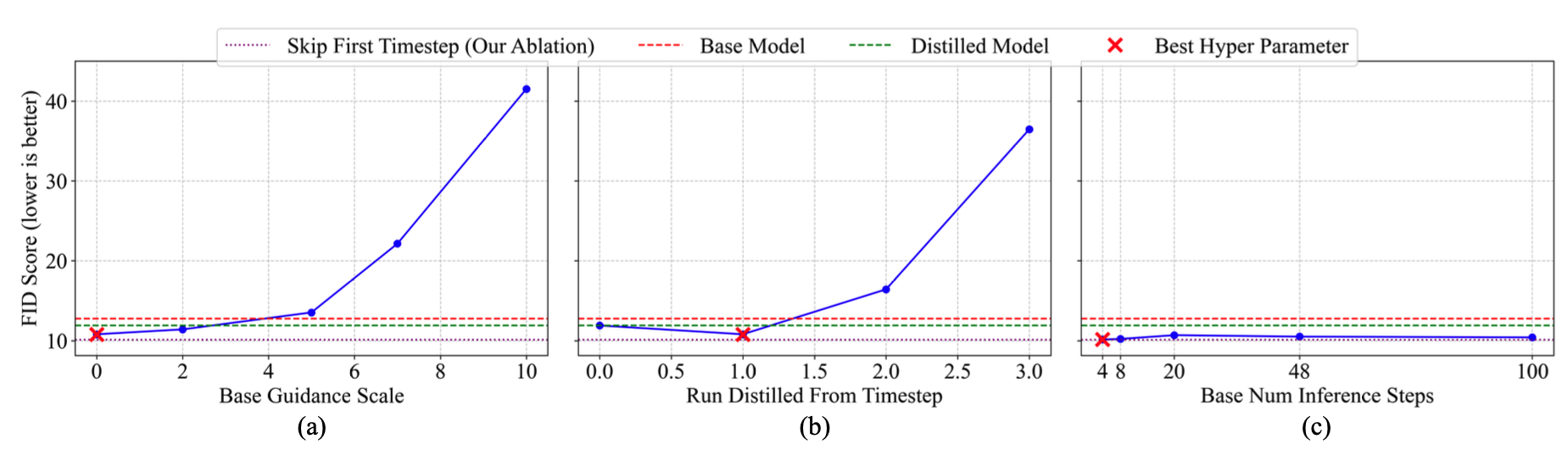
Our experiments revealed something unexpected: this hybrid approach not only restores the diversity lost during distillation but actually exceeds the diversity of the original base model. Meanwhile, it maintains nearly the same computational efficiency as fully distilled inference, creating images in just 0.64 seconds compared to the base model's 9.22 seconds.
We confirmed these results using both objective metrics like FID scores (which measure how well the generated images match real-world distributions) and by examining sample diversity within the same prompt (how different the outputs look when using different random seeds).

Practical Implications
This research challenges the traditional assumption that there must be a trade-off between speed and diversity in diffusion models. By understanding exactly where in the process diversity is determined, we can design hybrid approaches that maintain creative variety without sacrificing computational efficiency.
For practitioners, our findings mean that existing investments in control mechanisms like Concept Sliders, LoRAs, and custom fine-tunings can be seamlessly transferred between model types. This "control distillation" enables precise creative direction even in the fastest models.
Our DT-Visualization technique provides a valuable new tool for researchers and developers to debug and understand diffusion models, potentially leading to further innovations in model architecture and training.
How to cite
The paper can be cited as follows.
bibliography
Rohit Gandikota, David Bau. "Distilling Diversity and Control in Diffusion Models." arXiv preprint arXiv:2503.10637 (2025).
bibtex
@article{gandikota2025distilling,
title={Distilling Diversity and Control in Diffusion Models},
author={Rohit Gandikota and David Bau},
journal={arXiv preprint arXiv:2503.10637}
year={2025}
}